moabb.datasets.base.BaseDataset#
- class moabb.datasets.base.BaseDataset(subjects, sessions_per_subject, events, code, interval, paradigm, doi=None, unit_factor=1000000.0, *, selected_subjects=None, selected_sessions=None, return_all_modalities=False)[source]#
Bases:
objectAbstract Moabb BaseDataset.
Parameters required for all datasets.
- Parameters:
subjects (list of int) – List of subject number (or tuple or numpy array).
sessions_per_subject (int) – Number of sessions per subject (if varying, take minimum).
events (dict of str) – String codes for events matched with labels in the stim channel. Currently imagery codes can include:
left_hand,right_hand,hands,feet,rest,left_hand_right_foot,right_hand_left_foot,tongue,navigation,subtraction,word_ass(for word association).code (str) – Unique identifier for dataset, used in all plots. The code should be in CamelCase.
interval (list) – Imagery interval as defined in the dataset description, with 2 entries.
paradigm (str) – Defines what sort of dataset this is. One of
'p300','imagery', or'ssvep'.doi (str, optional) – DOI for the dataset.
return_all_modalities (bool | dict, optional) –
Controls which channel types are retained when data is picked:
False(default): only EEG channels are kept.True: all channels except stim are kept.dict: keyword arguments forwarded tomne.pick_types(), e.g.dict(eeg=True, eog=True)keeps EEG and EOG channels.stimis always forced toFalse.
- __init__(subjects, sessions_per_subject, events, code, interval, paradigm, doi=None, unit_factor=1000000.0, *, selected_subjects=None, selected_sessions=None, return_all_modalities=False)[source]#
Initialize function for the BaseDataset.
- property all_subjects#
Full list of subjects available in this dataset (unfiltered).
- convert_to_bids(path=None, subjects=None, overwrite=False, format='EDF', verbose=None, generate_figures=False)[source]#
Convert the dataset to BIDS format.
Saves the raw EEG data in a BIDS-compliant directory structure. Unlike the caching mechanism (see
CacheConfig), the files produced here do not contain a processing-pipeline hash (desc-<hash>) in their names, making the output a clean, shareable BIDS dataset.- Parameters:
path (str |
Path| None) – Directory under which the BIDS dataset will be written. IfNonethe default MNE data directory is used (same default as the rest of MOABB).subjects (list of int | None) – Subject numbers to convert. If
None, all subjects insubject_listare converted.overwrite (bool) – If
True, existing BIDS files for a subject are removed before saving. Default isFalse.format (str) – The file format for the raw EEG data. Supported values are
"EDF"(default),"BrainVision", and"EEGLAB".verbose (str | None) – Verbosity level forwarded to MNE/MNE-BIDS.
generate_figures (bool) – If
True, generate interactive neural signature HTML figures in{bids_root}/derivatives/neural_signatures/. Requiresplotly(pip install moabb[interactive]). Default isFalse.
- Returns:
bids_root – Path to the root of the written BIDS dataset.
- Return type:
Examples
>>> from moabb.datasets import AlexMI >>> dataset = AlexMI() >>> bids_root = dataset.convert_to_bids(path='/tmp/bids', subjects=[1])
Notes
Use
CacheConfigto configure caching forget_data(). Usemoabb.datasets.bids_interface.get_bids_rootto get the BIDS root path.Added in version 1.5.
- abstract data_path(subject, path=None, force_update=False, update_path=None, verbose=None) list[str | Path][source]#
Get path to local copy of a subject data.
- Parameters:
subject (int) – Number of subject to use
path (None | str) – Location of where to look for the data storing location. If None, the environment variable or config parameter
MNE_DATASETS_(dataset)_PATHis used. If it doesn’t exist, the “~/mne_data” directory is used. If the dataset is not found under the given path, the data will be automatically downloaded to the specified folder.force_update (bool) – Force update of the dataset even if a local copy exists.
update_path (bool | None Deprecated) – If True, set the MNE_DATASETS_(dataset)_PATH in mne-python config to the given path. If None, the user is prompted.
verbose (bool, str, int, or None) – If not None, override default verbose level (see
mne.verbose()).
- Returns:
path – Local path to the given data file. This path is contained inside a list of length one, for compatibility.
- Return type:
- download(subject_list=None, path=None, force_update=False, update_path=None, accept=False, verbose=None)[source]#
Download all data from the dataset.
This function is only useful to download all the dataset at once.
- Parameters:
subject_list (list of int | None) – List of subjects id to download, if None all subjects are downloaded.
path (None | str) – Location of where to look for the data storing location. If None, the environment variable or config parameter
MNE_DATASETS_(dataset)_PATHis used. If it doesn’t exist, the “~/mne_data” directory is used. If the dataset is not found under the given path, the data will be automatically downloaded to the specified folder.force_update (bool) – Force update of the dataset even if a local copy exists.
update_path (bool | None) – If True, set the MNE_DATASETS_(dataset)_PATH in mne-python config to the given path. If None, the user is prompted.
accept (bool) – Accept licence term to download the data, if any. Default: False
verbose (bool, str, int, or None) – If not None, override default verbose level (see
mne.verbose()).
- get_additional_metadata(subject: str, session: str, run: str)[source]#
Load additional metadata for a specific subject, session, and run.
This method is intended to be overridden by subclasses to provide additional metadata specific to the dataset. The metadata is typically loaded from an events.tsv file or similar data source.
- Parameters:
- Returns:
A DataFrame containing the additional metadata if available, otherwise None.
- Return type:
None |
pandas.DataFrame
- get_block_repetition(paradigm, subjects, block_list, repetition_list)[source]#
Select data for all provided subjects, blocks and repetitions.
subject -> session -> run -> block -> repetition
See also
- get_data(subjects=None, cache_config=None, process_pipeline=None)[source]#
Return the data corresponding to a list of subjects.
The returned data is a dictionary with the following structure:
data = {'subject_id' : {'session_id': {'run_id': run} } }
subjects are on top, then we have sessions, then runs. A sessions is a recording done in a single day, without removing the EEG cap. A session is constitued of at least one run. A run is a single contiguous recording. Some dataset break session in multiple runs.
Processing steps can optionally be applied to the data using the
*_pipelinearguments. These pipelines are applied in the following order:raw_pipeline->epochs_pipeline->array_pipeline. If a*_pipelineargument isNone, the step will be skipped. Therefore, thearray_pipelinemay either receive amne.io.Rawor amne.Epochsobject as input depending on whetherepochs_pipelineisNoneor not.- Parameters:
subjects (List of int) – List of subject number
cache_config (dict |
CacheConfig) – Configuration for caching of datasets. SeeCacheConfigfor details.process_pipeline (
sklearn.pipeline.Pipeline| None) – Optional processing pipeline to apply to the data. To generate an adequate pipeline, we recommend usingmoabb.make_process_pipelines(). This pipeline will receivemne.io.BaseRawobjects. The steps names of this pipeline should be elements ofStepType. According to their name, the steps should either return amne.io.BaseRaw, amne.Epochs, or anumpy.ndarray. This pipeline must be “fixed” because it will not be trained, i.e. no call tofitwill be made.
- Returns:
data – dict containing the raw data
- Return type:
Dict
- property metadata[source]#
Return structured metadata for this dataset.
Returns the DatasetMetadata object from the centralized catalog, or None if metadata is not available for this dataset.
- Returns:
The metadata object containing acquisition parameters, participant demographics, experiment details, and documentation. Returns None if no metadata is registered for this dataset.
- Return type:
DatasetMetadata| None
Examples
>>> from moabb.datasets import BNCI2014_001 >>> dataset = BNCI2014_001() >>> dataset.metadata.participants.n_subjects 9 >>> dataset.metadata.acquisition.sampling_rate 250.0
Examples using moabb.datasets.base.BaseDataset#

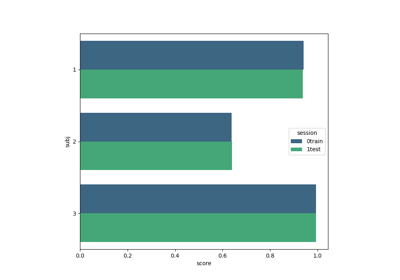
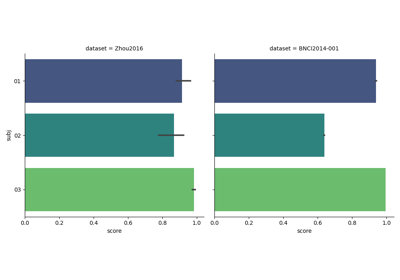


Tutorial 5: Combining Multiple Datasets into a Single Dataset
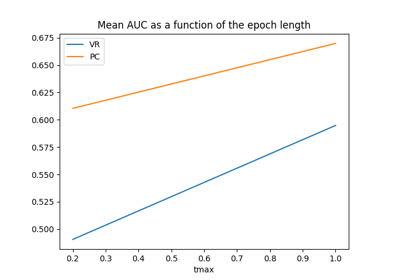
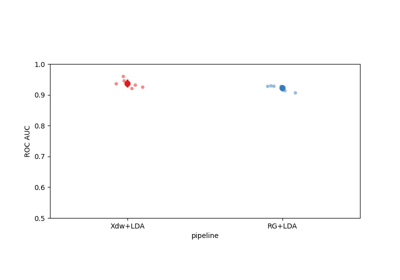
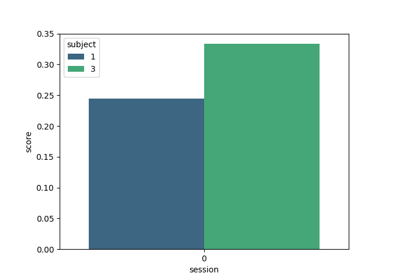



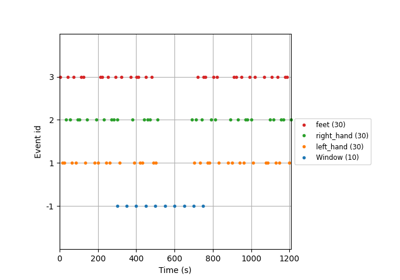
Tutorial: Within-Session Splitting on Real MI Dataset



Using X y data (epoched data) instead of continuous signal