

moabb.evaluations.CrossSubjectSplitter#
- class moabb.evaluations.CrossSubjectSplitter(cv_class: type[~sklearn.model_selection._split.BaseCrossValidator] = <class 'sklearn.model_selection._split.LeaveOneGroupOut'>, random_state: int | None = None, **cv_kwargs)[source]#
Data splitter for cross subject evaluation.
This splitter enables cross-subject evaluation by performing a Leave-One-Session-Out (LOSO) cross-validation on the dataset.
It assumes that the entire metainformation across all subjects is already loaded.
Unlike the CrossSubjectEvaluation class from moabb.evaluation, which manages the complete evaluation process end-to-end, this splitter is solely responsible for dividing the data into training and testing sets based on subjects.
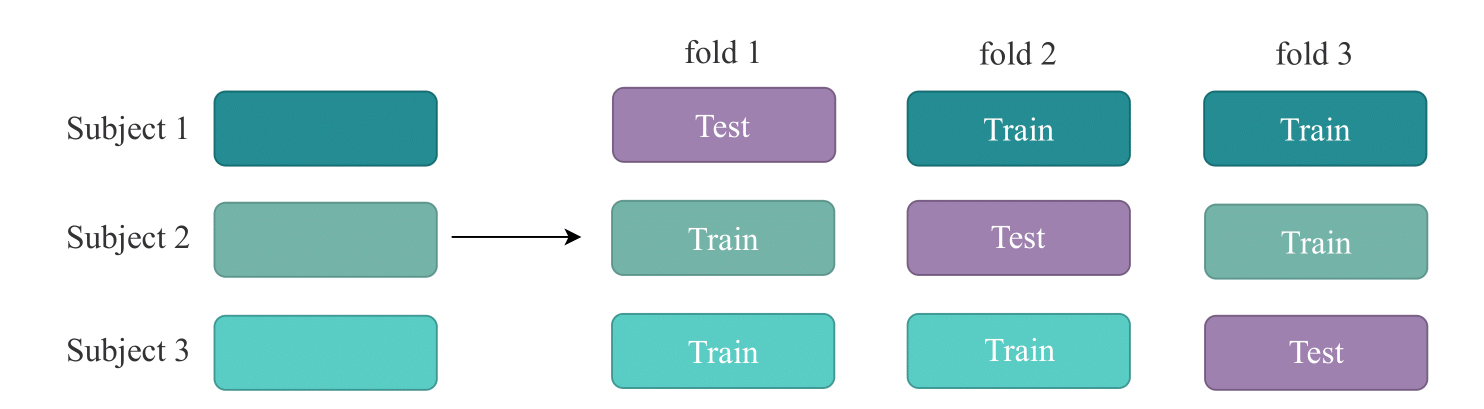
The splitting strategy for the subjects can be changed by passing the cv_class and cv_kwargs arguments. By default, it uses LeaveOneGroupOut, which performs Leave-One-Subject-Out cross-validation.
- Parameters:
cv_class (cross-validation class, default=LeaveOneGroupOut) – Cross-validation strategy for splitting the subjects between train and test sets. By default, use LeaveOneGroupOut, which keeps one subject as a test.
random_state (int, RandomState instance or None, default=None) – Controls the randomness of the cross-validation. Pass an int for reproducible output across multiple calls.
cv_kwargs (dict) – Additional arguments to pass to the inner cross-validation strategy.
- Yields:
train (ndarray) – The training set indices for that split.
test (ndarray) – The testing set indices for that split.
- get_n_splits(metadata)[source]#
Return the number of splits for the cross-validation.
The number of splits is the number of subjects times the number of splits of the inner cross-validation strategy.
We try to keep the same behaviour as the sklearn cross-validation classes.
- Parameters:
metadata (pd.DataFrame) – The metadata containing the subject and session information.
- Returns:
n_splits – The number of splits for the cross-validation
- Return type:
- split(y, metadata)[source]#
Generate indices to split data into training and test set.
- Parameters:
X (array-like of shape (n_samples, n_features)) – Training data, where n_samples is the number of samples and n_features is the number of features.
y (array-like of shape (n_samples,)) – The target variable for supervised learning problems.
groups (array-like of shape (n_samples,), default=None) – Group labels for the samples used while splitting the dataset into train/test set.
- Yields:
train (ndarray) – The training set indices for that split.
test (ndarray) – The testing set indices for that split.