


MOABB
Mother of all BCI Benchmarks
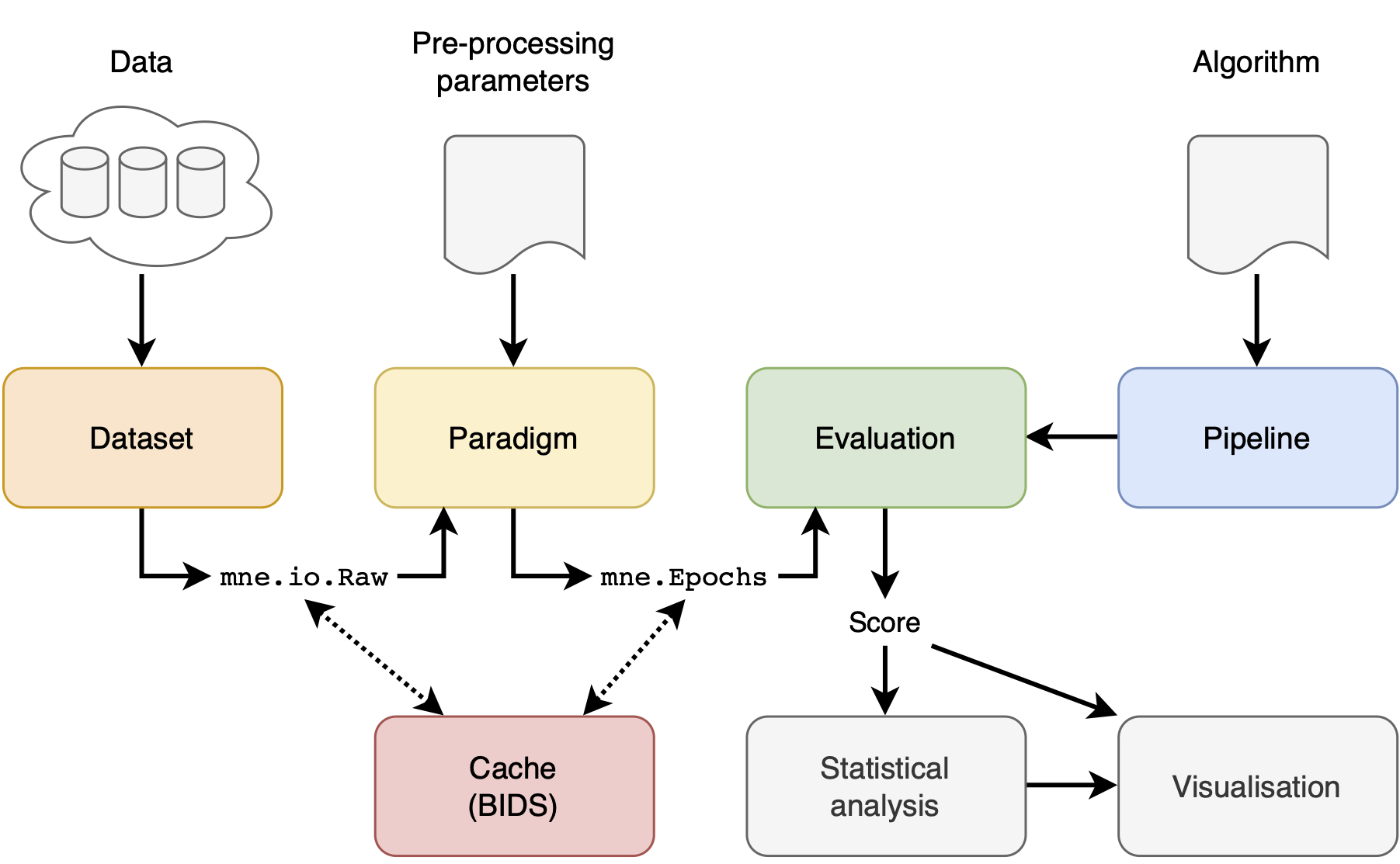
Reproducible benchmarking for EEG-based BCIs: compare pipelines across datasets, paradigms, and evaluation strategies with standardized results.
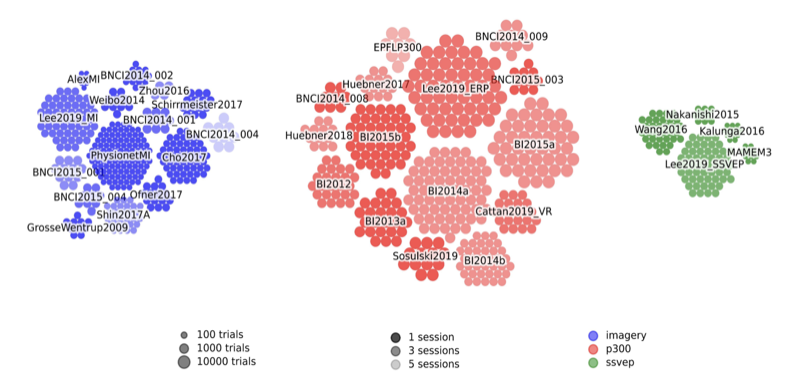
- 158 open EEG datasets, with 3500+ subjects (Motor Imagery, P300, SSVEP, c-VEP, and more)
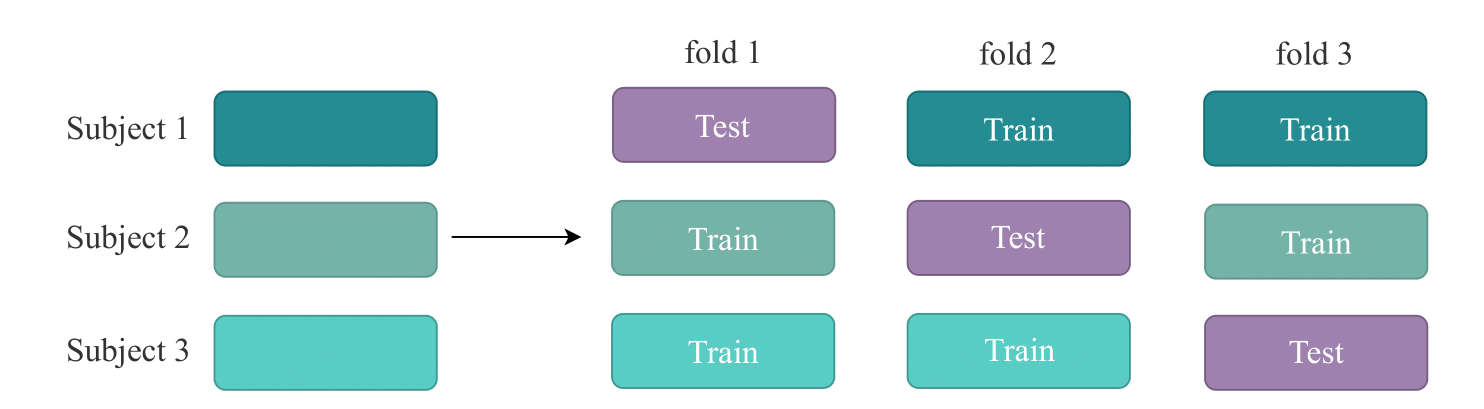
- Fair evaluations (within-session, cross-session, cross-subject)
- Built on MNE + scikit-learn for flexible pipelines





MOABB Homepage#

Mother of all BCI Benchmarks (MOABB)
Build a comprehensive benchmark of popular Brain-Computer Interface (BCI) algorithms applied on an extensive list of freely available EEG datasets.
Docs • Install • Examples • Benchmark • Datasets
![]()
![]()

![]()
Quickstart#
pip install moabb
import moabb
from moabb.datasets import BNCI2014_001
from moabb.evaluations import CrossSessionEvaluation
from moabb.paradigms import LeftRightImagery
from moabb.pipelines.features import LogVariance
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.pipeline import make_pipeline
moabb.set_log_level("info")
pipelines = {"LogVar+LDA": make_pipeline(LogVariance(), LDA())}
dataset = BNCI2014_001()
dataset.subject_list = dataset.subject_list[:2]
paradigm = LeftRightImagery(fmin=8, fmax=35)
evaluation = CrossSessionEvaluation(paradigm=paradigm, datasets=[dataset])
results = evaluation.process(pipelines)
print(results.head())
For full installation options and troubleshooting, see the documentation.
Disclaimer#
This is an open science project that may evolve depending on the need of the community.
The problem#
Brain-Computer Interfaces allow to interact with a computer using brain signals. In this project, we focus mostly on electroencephalographic signals (EEG), that is a very active research domain, with worldwide scientific contributions. Still:
Reproducible Research in BCI has a long way to go.
While many BCI datasets are made freely available, researchers do not publish code, and reproducing results required to benchmark new algorithms turns out to be trickier than it should be.
Performances can be significantly impacted by parameters of the preprocessing steps, toolboxes used and implementation “tricks” that are almost never reported in the literature.
As a result, there is no comprehensive benchmark of BCI algorithms, and newcomers are spending a tremendous amount of time browsing literature to find out what algorithm works best and on which dataset.
The solution#
The Mother of all BCI Benchmarks allows to:
Build a comprehensive benchmark of popular BCI algorithms applied on an extensive list of freely available EEG datasets.
The code is available on GitHub, serving as a reference point for the future algorithmic developments.
Algorithms can be ranked and promoted on a website, providing a clear picture of the different solutions available in the field.
This project will be successful when we read in an abstract “ … the proposed method obtained a score of 89% on the MOABB (Mother of All BCI Benchmarks), outperforming the state of the art by 5% …”.
Core Team#
This project is under the umbrella of NeuroTechX, the international community for NeuroTech enthusiasts.
The Mother of all BCI Benchmarks was founded by Alexander Barachant and Vinay Jayaram.
It is currently maintained by:
Contributors#
The MOABB is a community project, and we are always thankful to all the contributors!
Acknowledgements#
MOABB has benefited from the support of the following organizations:

What do we need?#
You! In whatever way you can help.
We need expertise in programming, user experience, software sustainability, documentation and technical writing and project management.
We’d love your feedback along the way.
Our primary goal is to build a comprehensive benchmark of popular BCI algorithms applied on an extensive list of freely available EEG datasets, and we’re excited to support the professional development of any and all of our contributors. If you’re looking to learn to code, try out working collaboratively, or translate your skills to the digital domain, we’re here to help.
Cite MOABB#
If you use MOABB in your experiments, please cite MOABB and the related publications:
Software Citation#
APA Format#
Aristimunha, B., Carrara, I., Guetschel, P., Sedlar, S., Rodrigues, P., Sosulski, J.,
Narayanan, D., Bjareholt, E., Barthelemy, Q., Schirrmeister, R. T., Kobler, R.,
Kalunga, E., Darmet, L., Gregoire, C., Abdul Hussain, A., Gatti, R., Goncharenko, V.,
Andreev, A., Thielen, J., Hajhassani, D., Begany, K., Moreau, T., Roy, Y., Jayaram, V.,
Barachant, A., & Chevallier, S. (2026). Mother of all BCI Benchmarks (MOABB) (Version 1.5.0).
Zenodo. https://doi.org/10.5281/zenodo.10034223
BibTeX Format#
@software{Aristimunha_Mother_of_all,
author = {Aristimunha, Bruno and
Carrara, Igor and
Guetschel, Pierre and
Sedlar, Sara and
Rodrigues, Pedro and
Sosulski, Jan and
Narayanan, Divyesh and
Bjareholt, Erik and
Barthelemy, Quentin and
Schirrmeister, Robin Tibor and
Kobler, Reinmar and
Kalunga, Emmanuel and
Darmet, Ludovic and
Gregoire, Cattan and
Abdul Hussain, Ali and
Gatti, Ramiro and
Goncharenko, Vladislav and
Andreev, Anton and
Thielen, Jordy and
Hajhassani, Davoud and
Begany, Katelyn and
Moreau, Thomas and
Roy, Yannick and
Jayaram, Vinay and
Barachant, Alexandre and
Chevallier, Sylvain},
title = {Mother of all BCI Benchmarks},
year = 2026,
publisher = {Zenodo},
version = {1.5.0},
url = {https://github.com/NeuroTechX/moabb},
doi = {10.5281/zenodo.10034223},
}
Scientific Publications#
If you want to cite the scientific contributions of MOABB, please use the following papers:
MOABB Benchmark Paper#
Sylvain Chevallier, Igor Carrara, Bruno Aristimunha, Pierre Guetschel, Sara Sedlar, Bruna Junqueira Lopes, Sébastien Velut, Salim Khazem, Thomas Moreau
“The largest EEG-based BCI reproducibility study for open science: the MOABB benchmark”
HAL: hal-04537061
Original MOABB Paper#
Vinay Jayaram and Alexandre Barachant
“MOABB: trustworthy algorithm benchmarking for BCIs”
Journal of Neural Engineering 15.6 (2018): 066011
📣 If you publish a paper using MOABB, please open an issue to let us know! We would love to hear about your work and help you promote it.
Contact us#
If you want to report a problem or suggest an enhancement, we’d love for you to open an issue at this GitHub repository because then we can get right on it.