MOABB Examples#
Explore quick, practical examples that demonstrate MOABB’s key modules and techniques.
Use these concise code samples as inspiration for your own analysis tasks.
For additional details, see the Getting Started tutorials or API reference.
The rest of the MOABB documentation pages are shown in the navigation menu, including the list of example datasets, how to cite MOABB, and explanations of the external library dependencies that MOABB uses, including Deep Learning, Code Carbon, Docs and others.
Getting Started!#
Tutorials: Step-by-step introductions to MOABB’s usage and concepts. These cover getting started with MOABB, using multiple datasets, benchmarking pipelines, and adding custom datasets in line with best practices for reproducible research.
Each tutorial focuses on a fundamental workflow for using moabb in your research!



Tutorial 5: Combining Multiple Datasets into a Single Dataset
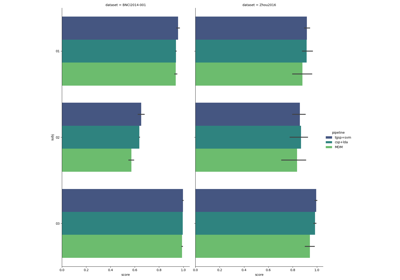
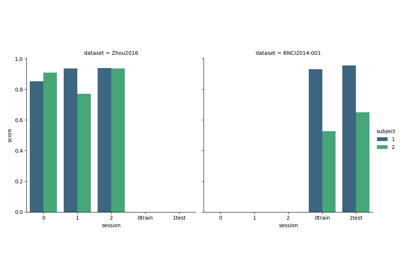
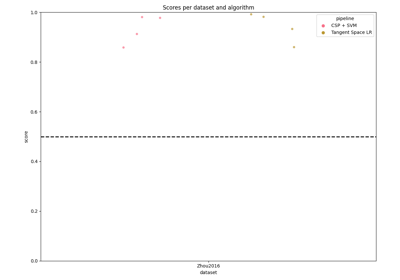
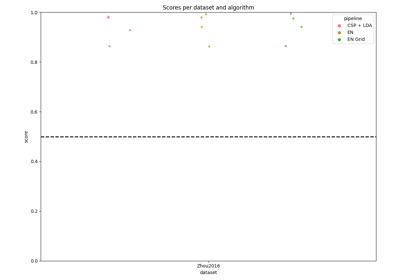
Paradigm-Specific Evaluation Examples (Within- & Cross-Session)#
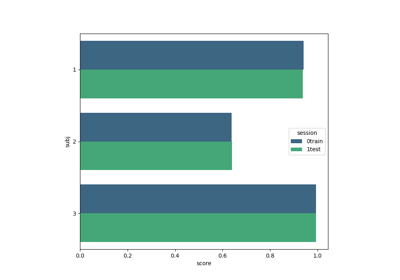
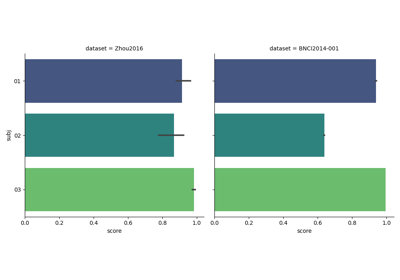
These examples demonstrate how to evaluate BCI algorithms on different paradigms (Motor Imagery, P300, SSVEP), covering within-session (training and testing on the same session) and transfer scenarios like cross-session or cross-subject evaluations. They reflect best practices in assessing model generalization across sessions and subjects in EEG research.
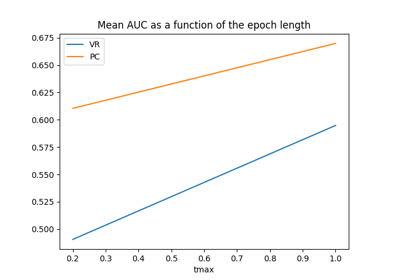
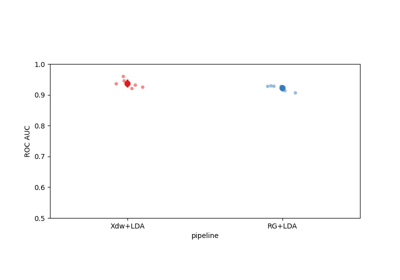
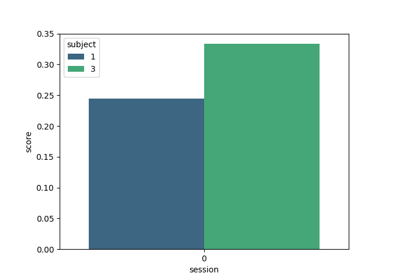
Data Management and Configuration#
Utility examples focused on data handling, configuration, and environment setup in MOABB. These scripts help ensure reproducible research through proper data management (download directories, standard formats) and optimized processing.





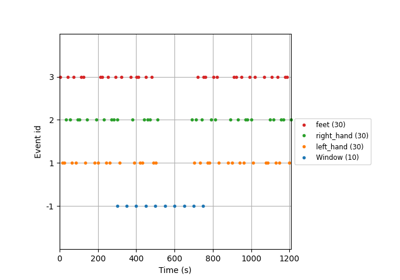
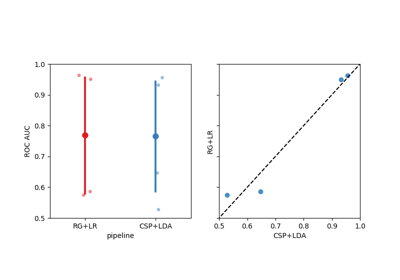
Benchmarking and Pipeline Evaluation#
Examples focusing on running benchmarks and comparing multiple models or configurations, following MOABB’s evaluation methodology. These scripts reflect EEG decoding best practices by evaluating algorithms under consistent conditions and tracking performance (and even resource usage).

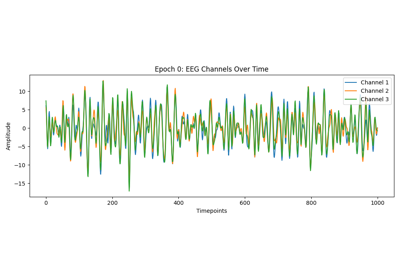
Tutorial: Within-Session Splitting on Real MI Dataset
Advanced examples#
These examples show various advanced topics:
using scikit-learn pipeline with MNE inputs
selecting electrodes or resampling signal
using filterbank approach in motor imagery
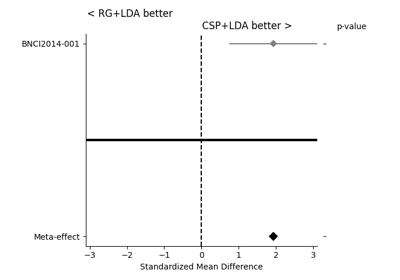
apply statistics for meta-analysis
using a gridsearch in within-subject decoding

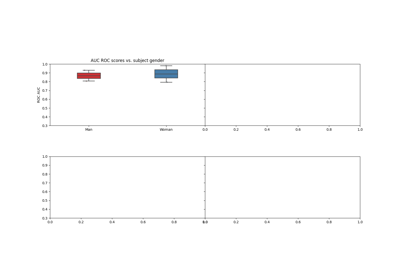
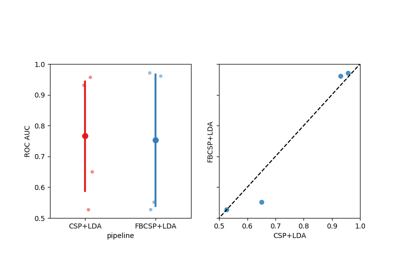
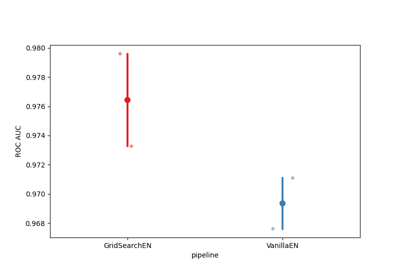
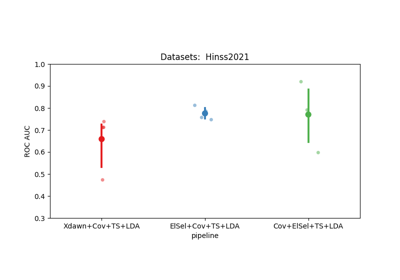
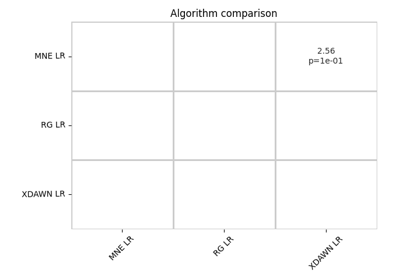


Riemannian Artifact Rejection as a Pre-processing Step
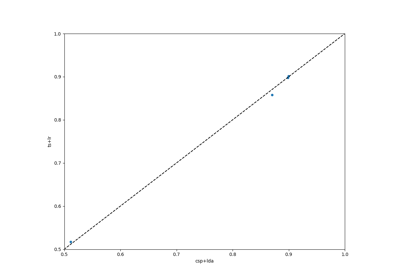


Using X y data (epoched data) instead of continuous signal
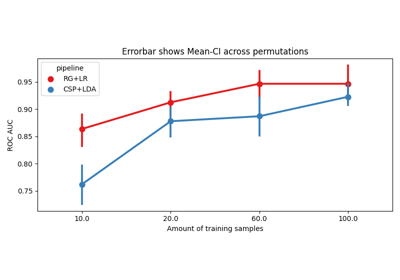
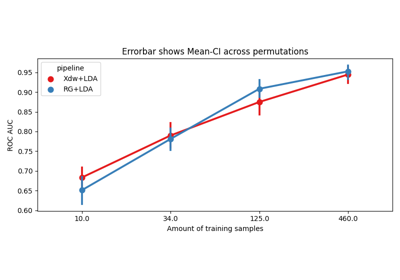
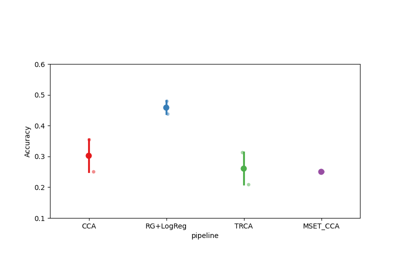
Evaluation with learning curve#
These examples demonstrate how to make evaluations using only a subset of available example. For example, if you consider a dataset with 100 trials for each class, you could evaluate several pipelines by using only a fraction of these trials. To ensure the robustness of the results, you need to specify the number of permutations. If you use 10 trials per class and 20 permutations, each pipeline will be evaluated on a subset of 10 trials chosen randomly, that will be repeated 20 times with different trial subsets.