

Note
Go to the end to download the full example code.
Within Session SSVEP#
This Example shows how to perform a within-session SSVEP analysis on the MAMEM dataset 3, using a CCA pipeline.
The within-session evaluation assesses the performance of a classification pipeline using a 5-fold cross-validation. The reported metric (here, accuracy) is the average of all fold.
# Authors: Sylvain Chevallier <sylvain.chevallier@uvsq.fr>
#
# License: BSD (3-clause)
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.pipeline import make_pipeline
import moabb
from moabb.datasets import Kalunga2016
from moabb.evaluations import WithinSessionEvaluation
from moabb.paradigms import SSVEP
from moabb.pipelines import SSVEP_CCA
warnings.simplefilter(action="ignore", category=FutureWarning)
warnings.simplefilter(action="ignore", category=RuntimeWarning)
moabb.set_log_level("info")
Loading Dataset#
Load 2 subjects of Kalunga2016 dataset
subj = [1, 3]
dataset = Kalunga2016()
dataset.subject_list = subj
Choose Paradigm#
We select the paradigm SSVEP, applying a bandpass filter (3-15 Hz) on the data and we keep only the first 3 classes, that is stimulation frequency of 13Hz, 17Hz and 21Hz.
Create Pipelines#
Use a Canonical Correlation Analysis classifier
interval = dataset.interval
freqs = paradigm.used_events(dataset)
pipeline = {}
pipeline["CCA"] = make_pipeline(SSVEP_CCA(n_harmonics=3))
Get Data (optional)#
To get access to the EEG signals downloaded from the dataset, you could use dataset.get_data(subjects=[subject_id]) to obtain the EEG under MNE format, stored in a dictionary of sessions and runs. Otherwise, paradigm.get_data(dataset=dataset, subjects=[subject_id]) allows to obtain the EEG data in scikit format, the labels and the meta information. In paradigm.get_data, the EEG are preprocessed according to the paradigm requirement.
# sessions = dataset.get_data(subjects=[3])
# X, labels, meta = paradigm.get_data(dataset=dataset, subjects=[3])
Evaluation#
The evaluation will return a DataFrame containing a single AUC score for each subject and pipeline.
overwrite = True # set to True if we want to overwrite cached results
evaluation = WithinSessionEvaluation(
paradigm=paradigm, datasets=dataset, suffix="examples", overwrite=overwrite
)
results = evaluation.process(pipeline)
print(results.head())
/home/runner/work/moabb/moabb/moabb/analysis/results.py:189: H5pyDeprecationWarning: Creating a dataset without passing data or dtype is deprecated. Pass an explicit dtype. Using dtype='f4' will keep the current default behaviour.
dset.create_dataset(
score time samples ... dataset pipeline codecarbon_task_name
0 0.333333 0.002734 48.0 ... Kalunga2016 CCA
1 0.333333 0.003121 48.0 ... Kalunga2016 CCA
[2 rows x 13 columns]
Plot Results#
Here we plot the results, indicating the score for each subject
plt.figure()
sns.barplot(data=results, y="score", x="session", hue="subject", palette="viridis")
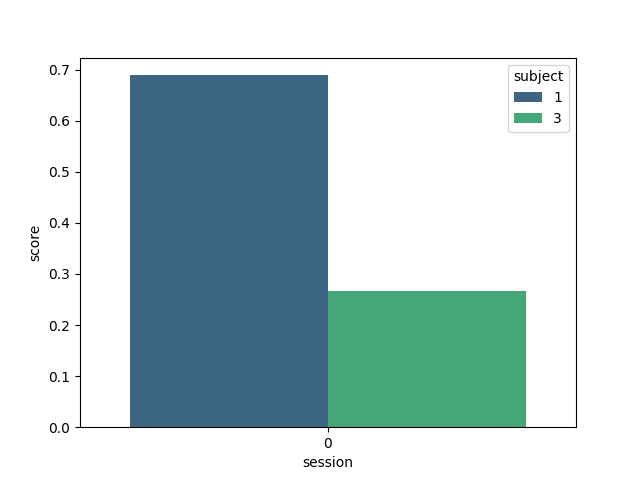
<Axes: xlabel='session', ylabel='score'>
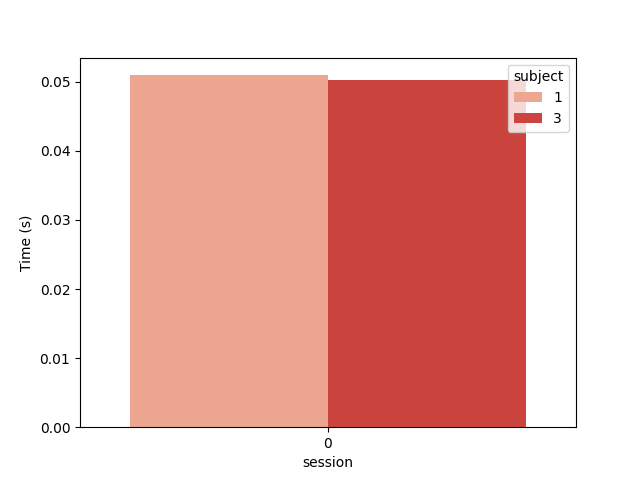
And the computation time in seconds
plt.figure()
ax = sns.barplot(data=results, y="time", x="session", hue="subject", palette="Reds")
ax.set_ylabel("Time (s)")
plt.show()
Total running time of the script: (0 minutes 31.785 seconds)
Run this example