Note
Click here to download the full example code
Cross-Session Motor Imagery#
This example show how to perform a cross session motor imagery analysis on the very popular dataset 2a from the BCI competition IV.
We will compare two pipelines :
CSP+LDA
Riemannian Geometry+Logistic Regression
We will use the LeftRightImagery paradigm. This will restrict the analysis to two classes (left hand versus right hand) and use AUC as metric.
The cross session evaluation context will evaluate performance using a leave one session out cross-validation. For each session in the dataset, a model is trained on every other session and performance are evaluated on the current session.
# Authors: Alexandre Barachant <alexandre.barachant@gmail.com>
# Sylvain Chevallier <sylvain.chevallier@uvsq.fr>
#
# License: BSD (3-clause)
import matplotlib.pyplot as plt
import seaborn as sns
from mne.decoding import CSP
from pyriemann.estimation import Covariances
from pyriemann.tangentspace import TangentSpace
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
import moabb
from moabb.datasets import BNCI2014_001
from moabb.evaluations import CrossSessionEvaluation
from moabb.paradigms import LeftRightImagery
moabb.set_log_level("info")
Create Pipelines#
Pipelines must be a dict of sklearn pipeline transformer.
The CSP implementation is based on the MNE implementation. We selected 8 CSP components, as usually done in the literature.
The Riemannian geometry pipeline consists in covariance estimation, tangent space mapping and finally a logistic regression for the classification.
pipelines = {}
pipelines["CSP+LDA"] = make_pipeline(CSP(n_components=8), LDA())
pipelines["RG+LR"] = make_pipeline(
Covariances(), TangentSpace(), LogisticRegression(solver="lbfgs")
)
Evaluation#
We define the paradigm (LeftRightImagery) and the dataset (BNCI2014_001). The evaluation will return a DataFrame containing a single AUC score for each subject / session of the dataset, and for each pipeline.
Results are saved into the database, so that if you add a new pipeline, it will not run again the evaluation unless a parameter has changed. Results can be overwritten if necessary.
paradigm = LeftRightImagery()
# Because this is being auto-generated we only use 2 subjects
dataset = BNCI2014_001()
dataset.subject_list = dataset.subject_list[:2]
datasets = [dataset]
overwrite = False # set to True if we want to overwrite cached results
evaluation = CrossSessionEvaluation(
paradigm=paradigm, datasets=datasets, suffix="examples", overwrite=overwrite
)
results = evaluation.process(pipelines)
print(results.head())
BNCI2014-001-CrossSession: 0%| | 0/2 [00:00<?, ?it/s]/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
BNCI2014-001-CrossSession: 50%|##### | 1/2 [00:05<00:05, 5.91s/it]/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
/home/runner/work/moabb/moabb/moabb/datasets/preprocessing.py:278: UserWarning: warnEpochs <Epochs | 24 events (all good), 2 – 6 s (baseline off), ~4.1 MB, data loaded,
'left_hand': 12
'right_hand': 12>
warn(f"warnEpochs {epochs}")
BNCI2014-001-CrossSession: 100%|##########| 2/2 [00:11<00:00, 5.79s/it]
BNCI2014-001-CrossSession: 100%|##########| 2/2 [00:11<00:00, 5.81s/it]
score time samples ... n_sessions dataset pipeline
0 0.950424 0.132384 144.0 ... 2 BNCI2014-001 RG+LR
1 0.963156 0.134643 144.0 ... 2 BNCI2014-001 RG+LR
2 0.574460 0.141480 144.0 ... 2 BNCI2014-001 RG+LR
3 0.585648 0.130814 144.0 ... 2 BNCI2014-001 RG+LR
4 0.931713 0.302630 144.0 ... 2 BNCI2014-001 CSP+LDA
[5 rows x 9 columns]
Plot Results#
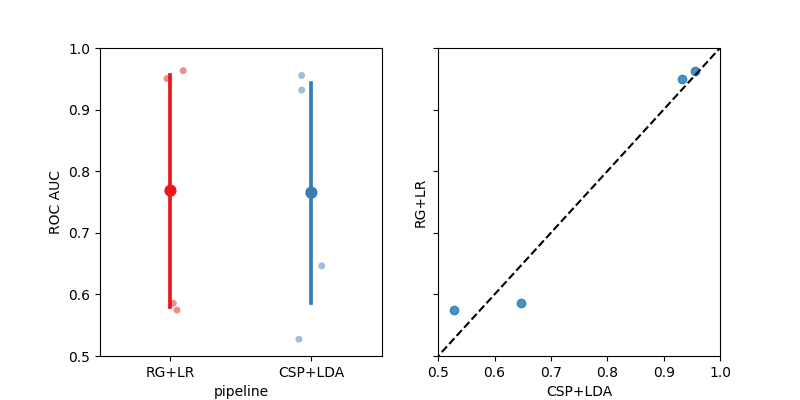
Here we plot the results. We first make a pointplot with the average performance of each pipeline across session and subjects. The second plot is a paired scatter plot. Each point representing the score of a single session. An algorithm will outperform another is most of the points are in its quadrant.
fig, axes = plt.subplots(1, 2, figsize=[8, 4], sharey=True)
sns.stripplot(
data=results,
y="score",
x="pipeline",
ax=axes[0],
jitter=True,
alpha=0.5,
zorder=1,
palette="Set1",
)
sns.pointplot(data=results, y="score", x="pipeline", ax=axes[0], palette="Set1")
axes[0].set_ylabel("ROC AUC")
axes[0].set_ylim(0.5, 1)
paired = results.pivot_table(
values="score", columns="pipeline", index=["subject", "session"]
)
paired = paired.reset_index()
sns.regplot(data=paired, y="RG+LR", x="CSP+LDA", ax=axes[1], fit_reg=False)
axes[1].plot([0, 1], [0, 1], ls="--", c="k")
axes[1].set_xlim(0.5, 1)
plt.show()
Total running time of the script: ( 0 minutes 16.272 seconds)
Estimated memory usage: 447 MB