moabb.paradigms.base.BaseProcessing#
- class moabb.paradigms.base.BaseProcessing(filters: List[Tuple[float, float]], tmin: float = 0.0, tmax: float | None = None, baseline: Tuple[float, float] | None = None, channels: List[str] | None = None, resample: float | None = None, overlap: float | None = None, reject_by_annotation: bool = True)[source]#
Base Processing.
Please use one of the child classes
- Parameters:
filters (list of list) – Bank of bandpass filter to apply. Defaults to
[[7, 35]].tmin (float) – Start time (in second) of the epoch, relative to the dataset specific task interval e.g. tmin = 1 would mean the epoch will start 1 second after the beginning of the task as defined by the dataset. Defaults to
0.0.tmax (float or None) – End time (in second) of the epoch, relative to the beginning of the dataset specific task interval. tmax = 5 would mean the epoch will end 5 second after the beginning of the task as defined in the dataset. If None, use the dataset value. Defaults to
None.baseline (None or tuple of length 2) – The time interval to consider as “baseline” when applying baseline correction. If None, do not apply baseline correction. If a tuple (a, b), the interval is between a and b (in seconds), including the endpoints. Correction is applied by computing the mean of the baseline period and subtracting it from the data (see mne.Epochs).
channels (list of str or None) – List of channel to select. If None, use all EEG channels available in the dataset. Defaults to
None.resample (float or None) – If not None, resample the eeg data with the sampling rate provided. Defaults to
None.overlap (float or None) – Overlap percentage (0-100) for the sliding window approach used in pseudo-online evaluation. If None, no overlap is applied. When overlap is used, windows may cross event boundaries; such windows are kept and labeled using a majority vote over the events they cover. Defaults to
None.reject_by_annotation (bool) – If True, reject epochs overlapping annotations whose description starts with
bad. Defaults toTrue.
- abstract property datasets#
Property that define the list of compatible datasets.
- get_data(dataset, subjects=None, return_epochs=False, return_raws=False, cache_config=None, postprocess_pipeline=None, process_pipelines=None, additional_metadata: Literal['all'] | list[str] = None, n_jobs=1)[source]#
Return the data for a list of subject.
return the data, labels and a dataframe with metadata. the dataframe will contain at least the following columns
subject : the subject indice
session : the session indice
run : the run indice
- Parameters:
dataset (
BaseDataset) – A dataset instance.return_epochs (boolean) – This flag specifies whether to return only the data array or the complete processed mne.Epochs
return_raws (boolean) – To return raw files and events, to ensure compatibility with braindecode. Mutually exclusive with return_epochs
cache_config (dict |
CacheConfig) – Configuration for caching of datasets. SeeCacheConfigfor details.postprocess_pipeline (
sklearn.pipeline.Pipeline| None) – Optional pipeline to apply to the data after the preprocessing. This pipeline will either receivemne.io.BaseRaw,mne.Epochsornumpy.ndarrayas input, depending on the values ofreturn_epochsandreturn_raws. This pipeline must return anumpy.ndarray. This pipeline must be “fixed” because it will not be trained, i.e. no call tofitwill be made.process_pipelines (
sklearn.pipeline.Pipeline| None) – Optional pipeline to apply to the data after the preprocessing. You must set thereturn_epochsandreturn_rawsparameters accordingly, i.e., if your custom pipeline returns raw objects, you must also setreturn_raws=True, otherwise you will get unexpected results. Only use it if you know what you are doing.additional_metadata (Literal["all"] | list[str] | None) – Additional metadata to be loaded from the dataset. If None, the default metadata will be loaded containing subject, session and run. If “all”, all columns of the events.tsv file will be loaded. A list of column names can be passed to just select these columns in addition to the three default values mentioned before. This parameter works regardless of the return type (epochs, raws, or array).
n_jobs (int) – Number of jobs to run in parallel over subjects when loading and preprocessing the data. Default
1(sequential). Per-subject processing is independent, so this gives a near-linear speedup for datasets with many subjects, with identical numerical results.
- Returns:
X (
numpy.ndarray|mne.Epochs) – the data that will be used as features for the model Note: if return_epochs=True, this ismne.Epochs; if return_epochs=False, this isnumpy.ndarray.labels (
numpy.ndarray) – the labels for training / evaluating the modelmetadata (
pandas.DataFrame) – A dataframe containing the metadata.
- abstractmethod is_valid(dataset)[source]#
Verify the dataset is compatible with the paradigm.
This method is called to verify dataset is compatible with the paradigm.
This method should raise an error if the dataset is not compatible with the paradigm. This is for example the case if the dataset is an ERP dataset for motor imagery paradigm, or if the dataset does not contain any of the required events.
- Parameters:
dataset (
BaseDataset) – The dataset to verify.
- make_labels_pipeline(dataset, return_epochs=False, return_raws=False)[source]#
Returns the pipeline that extracts the labels from the output of the postprocess_pipeline. Refer to the arguments of
get_data()for more information.
- make_process_pipelines(dataset, return_epochs=False, return_raws=False, postprocess_pipeline=None)[source]#
Create pre-processing pipelines for the data.
Return the pre-processing pipelines corresponding to this paradigm (one per frequency band).
- Parameters:
dataset (BaseDataset) – The dataset instance.
return_epochs (bool) – Specify if needed to return epochs instead of ndarray. Defaults to
False.return_raws (bool) – Specify if needed to return raws instead of ndarray. Defaults to
False.postprocess_pipeline (
sklearn.pipeline.Pipelineor None) – Optional pipeline to apply to the data after the preprocessing. Defaults toNone. This pipeline will either receivemne.io.BaseRaw,mne.Epochsornumpy.ndarrayas input, depending on the values ofreturn_epochsandreturn_raws. This pipeline must return anumpy.ndarray. This pipeline must be “fixed” because it will not be trained, i.e. no call tofitwill be made.
- match_all(datasets: List[BaseDataset], shift=-0.5, channel_merge_strategy: str = 'intersect', ignore=None)[source]#
Initialize this paradigm to match all datasets in parameter:
self.resample is set to match the minimum frequency in all datasets, minus shift. If the frequency is 128 for example, then MNE can return 128 or 129 samples depending on the dataset, even if the length of the epochs is 1s Setting shift=-0.5 solves this particular issue.
self.channels is initialized with the channels which are common to all datasets.
- Parameters:
datasets (list of
BaseDataset) – List of dataset instances.shift (float) – Shift the sampling frequency by this value E.g.: if sampling=128 and shift=-0.5, then it returns 127.5 Hz
channel_merge_strategy (str) – Accepts two values (defaults to
'intersect'): - ‘intersect’: keep only channels common to all datasets - ‘union’: keep all channels from all datasets, removing duplicateignore (List[string]) – A list of channels to ignore
..versionadded: – 0.6.0:
- prepare_process(dataset)[source]#
Prepare processing of raw files.
This function allows to set parameter of the paradigm class prior to the preprocessing (process_raw). Does nothing by default and could be overloaded if needed.
- Parameters:
dataset (
BaseDataset) – The dataset corresponding to the raw file. mainly use to access dataset specific information.
Examples using moabb.paradigms.base.BaseProcessing#



Tutorial 5: Combining Multiple Datasets into a Single Dataset


Tutorial: Within-Session Splitting on Real MI Dataset
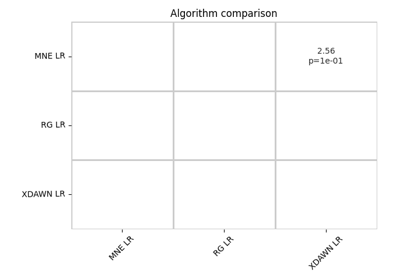


Riemannian Artifact Rejection as a Pre-processing Step
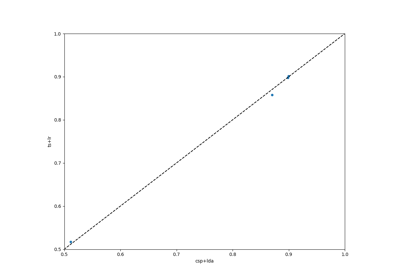


Using X y data (epoched data) instead of continuous signal