

Note
Go to the end to download the full example code.
Cross-Session on Multiple Datasets#
This example shows how to perform a cross-session analysis on two MI datasets using a CSP+LDA pipeline
The cross session evaluation context will evaluate performance using a leave one session out cross-validation. For each session in the dataset, a model is trained on every other session and performance are evaluated on the current session.
# Authors: Sylvain Chevallier <sylvain.chevallier@uvsq.fr>
#
# License: BSD (3-clause)
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
from mne.decoding import CSP
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.pipeline import make_pipeline
import moabb
from moabb.datasets import BNCI2014_001, Zhou2016
from moabb.evaluations import CrossSessionEvaluation
from moabb.paradigms import LeftRightImagery
warnings.simplefilter(action="ignore", category=FutureWarning)
warnings.simplefilter(action="ignore", category=RuntimeWarning)
moabb.set_log_level("info")
Loading Dataset#
Load 2 subjects of BNCI 2014-004 and Zhou2016 datasets, with 2 session each
subjects_list = [1, 2]
datasets = [Zhou2016(), BNCI2014_001()]
for d in datasets:
# replace the subject list
d.subject_list = subjects_list
Choose Paradigm#
We select the paradigm MI, applying a bandpass filter (8-35 Hz) on the data and we will keep only left- and right-hand motor imagery
paradigm = LeftRightImagery(fmin=8, fmax=35)
Create Pipelines#
Use the Common Spatial Patterns with 8 components and a Linear Discriminant Analysis classifier.
pipeline = {}
pipeline["CSP+LDA"] = make_pipeline(CSP(n_components=8), LDA())
Get Data (optional)#
To get access to the EEG signals downloaded from the dataset, you could use dataset.get_data(subjects=[subject_id]) to obtain the EEG under an MNE format, stored in a dictionary of sessions and runs. Otherwise, paradigm.get_data(dataset=dataset, subjects=[subject_id]) allows to obtain the EEG data in sklearn format, the labels and the meta information. The data are preprocessed according to the paradigm requirements.
# X_all, labels_all, meta_all = [], [], []
# for d in datasets:
# # sessions = d.get_data(subjects=[2])
# X, labels, meta = paradigm.get_data(dataset=d, subjects=[2])
# X_all.append(X)
# labels_all.append(labels)
# meta_all.append(meta)
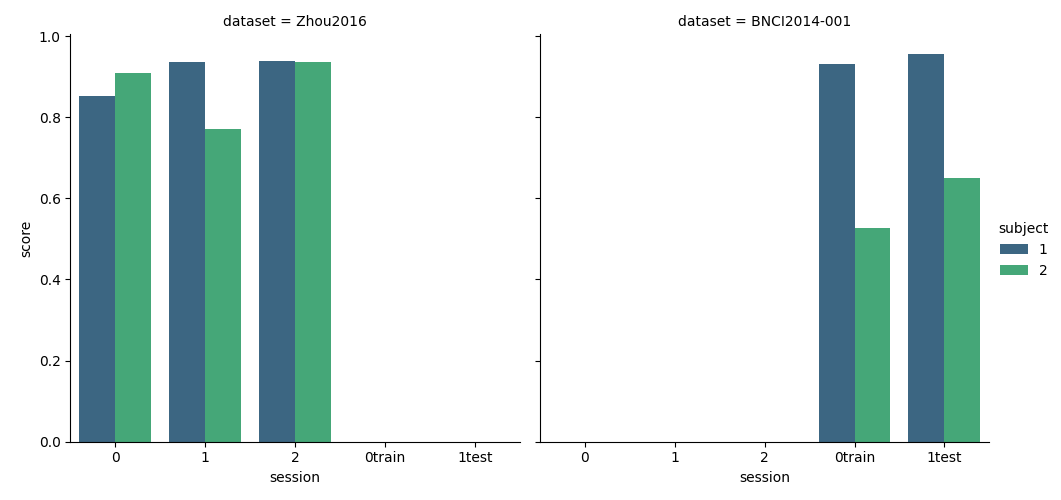
Evaluation#
The evaluation will return a DataFrame containing a single AUC score for each subject / session of the dataset, and for each pipeline.
overwrite = True # set to True if we want to overwrite cached results
evaluation = CrossSessionEvaluation(
paradigm=paradigm, datasets=datasets, suffix="examples", overwrite=overwrite
)
results = evaluation.process(pipeline)
print(results.head())
score time ... pipeline codecarbon_task_name
0 0.85113 0.251549 ... CSP+LDA 37594e21-1164-4c3c-a48b-48dd0b6dc0ef
1 0.93640 0.236277 ... CSP+LDA 3ed2f0d8-968b-4254-9024-3b0410c6577d
2 0.93960 0.249662 ... CSP+LDA 2c782690-58df-4346-a424-6f1266a4c9eb
3 0.90800 0.158185 ... CSP+LDA 36049b74-c932-45a3-900a-bd80d88ea43f
4 0.77037 0.164946 ... CSP+LDA d5696a18-7518-419c-bd89-2b12e61a4d3c
[5 rows x 13 columns]
Plot Results#
Here we plot the results, indicating the score for each session and subject
Total running time of the script: (0 minutes 39.795 seconds)
Run this example