

Note
Go to the end to download the full example code.
Euclidean Alignment for cross-subject transfer#
EEG covariance statistics drift from subject to subject (and session to session): the same mental task produces differently-shaped data on each recording. That domain shift is the main reason a decoder trained on one set of subjects transfers poorly to a new one. Euclidean Alignment (EA) removes it with a single, label-free whitening step — cheap enough to put in front of any model, deep or classical [1].
In a systematic evaluation across MOABB motor-imagery datasets, Junqueira,
Aristimunha, Chevallier & de Camargo (2024) [2] showed that aligning each
recording with EA before training a shared deep model improved target-subject
decoding by +4.33% on average and cut convergence time by more than 70% —
for almost no compute and no extra labels. This example reproduces the core
idea on the workhorse CSP+LDA motor-imagery pipeline using
moabb.datasets.preprocessing.EuclideanAlignment.
Each trial \(X_i\) is whitened by the inverse square root of the Euclidean (arithmetic) mean of the per-trial covariances of its recording,
so after alignment every recording shares an identity-like average covariance
and the subjects become comparable. We apply EA per subject (the
transductive, per-recording form — fit_transform() on one recording; it
uses only the trial covariances, never the labels) and compare leave-one-subject
-out decoding with and without it.
# Authors: Bruno Aristimunha <b.aristimunha@gmail.com>
#
# License: BSD (3-clause)
import matplotlib.pyplot as plt
import mne
import numpy as np
from mne.decoding import CSP
from pyriemann.estimation import Covariances
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.metrics import roc_auc_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import LabelEncoder
import moabb
from moabb.datasets import BNCI2014_001
from moabb.datasets.preprocessing import EuclideanAlignment
from moabb.paradigms import LeftRightImagery
moabb.set_log_level("info")
mne.set_log_level("WARNING") # keep the gallery output readable
Load the data per subject#
We use the BCI Competition IV 2a dataset (moabb.datasets.BNCI2014_001)
and the moabb.paradigms.LeftRightImagery paradigm (left- vs right-hand
motor imagery, scored with ROC-AUC). We keep the trials of each subject
separate, because Euclidean Alignment is defined per recording.
paradigm = LeftRightImagery()
dataset = BNCI2014_001()
subjects = dataset.subject_list[:8]
# Pull each subject's trials once; X is (n_trials, n_channels, n_times).
data = {}
for subject in subjects:
X, labels, _ = paradigm.get_data(dataset, [subject])
data[subject] = (X, LabelEncoder().fit_transform(labels))
Euclidean Alignment reduces the between-subject covariance shift#
Before any classification, we can see what EA does. For every subject we compute the mean trial covariance, then measure how far apart the subjects are as the average pairwise distance between those mean covariances. EA pulls them together — each subject’s mean covariance becomes ~identity.
def mean_covariance(X):
"""Euclidean mean of the per-trial covariances of one recording."""
return Covariances("oas").transform(X).mean(axis=0)
def between_subject_dispersion(means):
"""Average pairwise Frobenius distance between subject mean covariances."""
dists = [
np.linalg.norm(means[i] - means[j])
for i in range(len(means))
for j in range(i + 1, len(means))
]
return float(np.mean(dists))
raw_means, aligned_means = [], []
for subject in subjects:
X, _ = data[subject]
raw_means.append(mean_covariance(X))
# Per-subject (transductive) Euclidean Alignment: label-free, leakage-free.
X_aligned = EuclideanAlignment().fit_transform(X)
aligned_means.append(mean_covariance(X_aligned))
dispersion = {
"No alignment": between_subject_dispersion(raw_means),
"Euclidean Alignment": between_subject_dispersion(aligned_means),
}
print("Between-subject covariance dispersion:", dispersion)
fig, ax = plt.subplots(figsize=(5, 4))
ax.bar(dispersion.keys(), dispersion.values(), color=["#999999", "#0072B2"])
ax.set_ylabel("Mean pairwise distance between\nsubject covariances (Frobenius)")
ax.set_title("Euclidean Alignment shrinks the\nbetween-subject domain shift")
fig.tight_layout()
plt.show()
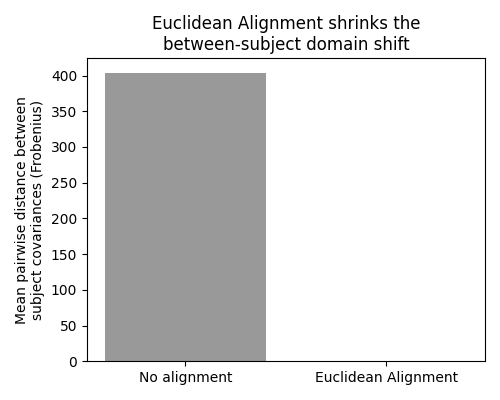
Between-subject covariance dispersion: {'No alignment': 404.171451512519, 'Euclidean Alignment': 0.5087545462974774}
Leave-one-subject-out decoding, with and without alignment#
Now the payoff. For each held-out subject we train a standard CSP+LDA pipeline on the other subjects and test on the held-out one — the cross-subject transfer setting. We run it twice: on the raw trials, and on trials that have each been Euclidean-aligned per subject.
CSP+LDA is a Euclidean classifier and is therefore sensitive to the covariance shift EA removes. (Riemannian tangent-space pipelines already recenter covariances internally, so they benefit less — EA is most valuable for Euclidean and deep models, exactly the setting of [2].)
def decode_loso(aligned):
"""Leave-one-subject-out ROC-AUC, optionally with per-subject EA."""
scores = []
for test_subject in subjects:
train_subjects = [s for s in subjects if s != test_subject]
def prep(subject):
X, y = data[subject]
if aligned:
X = EuclideanAlignment().fit_transform(X)
return X, y
X_train = np.concatenate([prep(s)[0] for s in train_subjects])
y_train = np.concatenate([prep(s)[1] for s in train_subjects])
X_test, y_test = prep(test_subject)
clf = make_pipeline(CSP(n_components=8), LDA())
clf.fit(X_train, y_train)
proba = clf.predict_proba(X_test)[:, 1]
scores.append(roc_auc_score(y_test, proba))
return np.array(scores)
raw_scores = decode_loso(aligned=False)
aligned_scores = decode_loso(aligned=True)
for subject, raw, aligned in zip(subjects, raw_scores, aligned_scores):
print(f"subject {subject}: raw={raw:.3f} aligned={aligned:.3f}")
print(
f"mean: raw={raw_scores.mean():.3f} aligned={aligned_scores.mean():.3f} "
f"(EA wins on {(aligned_scores > raw_scores).sum()}/{len(subjects)} subjects)"
)
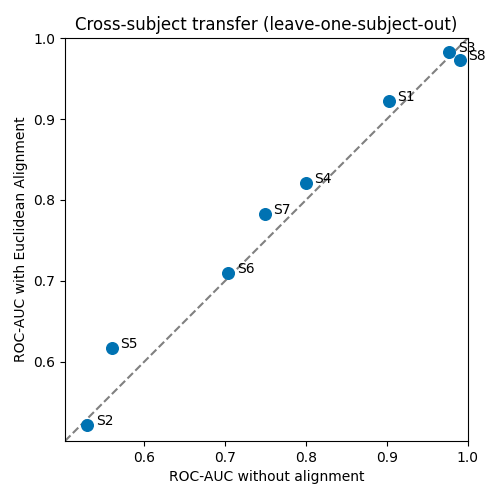
subject 1: raw=0.903 aligned=0.922
subject 2: raw=0.530 aligned=0.522
subject 3: raw=0.977 aligned=0.983
subject 4: raw=0.799 aligned=0.821
subject 5: raw=0.560 aligned=0.617
subject 6: raw=0.704 aligned=0.709
subject 7: raw=0.749 aligned=0.783
subject 8: raw=0.990 aligned=0.973
mean: raw=0.777 aligned=0.791 (EA wins on 6/8 subjects)
A point per held-out subject: above the diagonal means Euclidean Alignment helped that subject’s cross-subject transfer.
fig, ax = plt.subplots(figsize=(5, 5))
ax.scatter(raw_scores, aligned_scores, c="#0072B2", s=70, zorder=3)
for subject, raw, aligned in zip(subjects, raw_scores, aligned_scores):
ax.annotate(f"S{subject}", (raw, aligned), textcoords="offset points", xytext=(6, 0))
lims = [min(raw_scores.min(), aligned_scores.min()) - 0.02, 1.0]
ax.plot(lims, lims, "--", color="grey", zorder=1)
ax.set_xlim(lims)
ax.set_ylim(lims)
ax.set_xlabel("ROC-AUC without alignment")
ax.set_ylabel("ROC-AUC with Euclidean Alignment")
ax.set_title("Cross-subject transfer (leave-one-subject-out)")
ax.set_aspect("equal")
fig.tight_layout()
plt.show()
Using it inside a MOABB evaluation#
Above we used the transductive per-recording form (fit_transform on
each subject). EuclideanAlignment is
also a regular scikit-learn transformer, so its inductive, leakage-free
form drops straight into a pipeline for any MOABB evaluation: fit learns
the reference whitener from the training trials only and transform reuses
it on the test trials. For example:
from moabb.evaluations import CrossSubjectEvaluation
pipelines = {
"EA+CSP+LDA": make_pipeline(
EuclideanAlignment(), CSP(n_components=8), LDA()
)
}
evaluation = CrossSubjectEvaluation(paradigm=paradigm, datasets=[dataset])
results = evaluation.process(pipelines)
For the full deep-learning story — where EA shines most, improving target accuracy by +4.33% and cutting training time by >70% — see Junqueira et al. (2024) [2].
References#
Total running time of the script: (1 minutes 37.083 seconds)
Run this example