moabb.datasets.preprocessing.EuclideanAlignment#
- class moabb.datasets.preprocessing.EuclideanAlignment(estimator='lwf')[source]#
Bases:
TransformerMixin,BaseEstimatorEuclidean Alignment of trials (He & Wu, 2020).
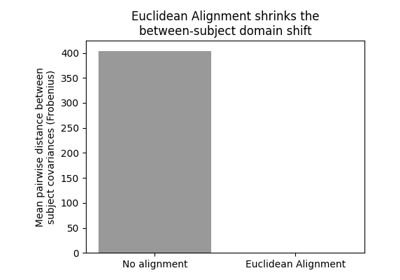
Euclidean Alignment (EA) removes the per-domain (subject / session / recording) covariance shift that makes a model trained on one set of recordings transfer poorly to another. It is the simplest member of a larger family of trial-alignment methods — others recenter on the Riemannian or log-Euclidean mean — and is the one most used with deep networks because it is cheap, label-free, and leaves the data as raw trials a network can ingest [He2020] [Junqueira2024].
Each trial is whitened by the inverse square root of a single reference covariance,
\[\bar{C} = \frac{1}{N} \sum_{i=1}^{N} C_i, \qquad \tilde{X}_i = \bar{C}^{-1/2} X_i ,\]where \(C_i\) is the spatial covariance of trial \(X_i\) and \(\bar{C}\) is their arithmetic (Euclidean) mean. After alignment the trials share an identity-like average covariance, so the domain shift that lived in the second-order statistics is gone.
The transformer is inductive by default:
fit()learns \(\bar{C}^{-1/2}\) from the training trials andtransform()re-applies that same whitener to unseen trials, so no test information leaks into the alignment (the leakage that the transductive, fit-on-everything form silently introduces). Callingfit_transform()on a single recording recovers the usual transductive, per-recording EA people hand-roll — same object, no second class.Unlike
pyriemann.transfer.TLCenter(withmetric="euclid"), which recenters covariance matrices for a Riemannian classifier, this operates directly on the(n_trials, n_channels, n_times)trials, so it drops in front of any time-series model (CSP, EEGNet, …).- Parameters:
estimator (str, default "lwf") – Covariance estimator passed to
pyriemann.geometry.covariance.covariances(). The shrinkage default"lwf"(Ledoit-Wolf) keeps the per-trial covariances symmetric positive-definite — and hence the reference mean invertible — even on short or noisy trials, where the plain sample covariance ("scm"/"cov") can be ill-conditioned.
- inv_sqrt_ref_#
Inverse square root \(\bar{C}^{-1/2}\) of the reference mean covariance learned in
fit(); the whitening matrix applied intransform().- Type:
ndarray, shape (n_channels, n_channels)
See also
pyriemann.transfer.TLCenterNotes
Accepts an
mne.BaseEpochs(read viaget_data) or an ndarray of shape(n_trials, n_channels, n_times);transform()returns an ndarray of the same shape.pyriemann >= 0.11is already a hard moabb dependency, so this adds no new requirement.References
[He2020]He, H., & Wu, D. (2020). Transfer learning for brain-computer interfaces: A Euclidean space data alignment approach. IEEE Transactions on Biomedical Engineering, 67(2), 399-410. https://doi.org/10.1109/TBME.2019.2913914
[Junqueira2024]Junqueira, B., Aristimunha, B., Chevallier, S., & de Camargo, R. Y. (2024). A systematic evaluation of Euclidean alignment with deep learning for EEG decoding. Journal of Neural Engineering, 21(3), 036038. https://doi.org/10.1088/1741-2552/ad4f18
- fit_transform(X, y=None, **fit_params)[source]#
Fit to data, then transform it.
Fits transformer to X and y with optional parameters fit_params and returns a transformed version of X.
- Parameters:
X (array-like of shape (n_samples, n_features)) – Input samples.
y (array-like of shape (n_samples,) or (n_samples, n_outputs), default=None) – Target values (None for unsupervised transformations).
**fit_params (dict) – Additional fit parameters. Pass only if the estimator accepts additional params in its fit method.
- Returns:
X_new – Transformed array.
- Return type:
ndarray array of shape (n_samples, n_features_new)
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
routing – A
MetadataRequestencapsulating routing information.- Return type:
MetadataRequest
- set_output(*, transform=None)[source]#
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
transform ({"default", "pandas", "polars"}, default=None) –
Configure output of transform and fit_transform.
”default”: Default output format of a transformer
”pandas”: DataFrame output
”polars”: Polars output
None: Transform configuration is unchanged
Added in version 1.4: “polars” option was added.
- Returns:
self – Estimator instance.
- Return type:
estimator instance
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance