

moabb.evaluations.CrossSessionSplitter#
- class moabb.evaluations.CrossSessionSplitter(cv_class: type[~sklearn.model_selection._split.BaseCrossValidator] = <class 'sklearn.model_selection._split.LeaveOneGroupOut'>, shuffle: bool = False, random_state: int | None = None, **cv_kwargs)[source]#
Data splitter for cross session evaluation.
This splitter enables cross-session evaluation by performing a Leave-One-Session-Out (LOSO) cross-validation on data from each subject.
It assumes that the entire metainformation across all subjects is already loaded.
Unlike the CrossSessionEvaluation class from moabb.evaluation, which manages the complete evaluation process end-to-end, this splitter is solely responsible for dividing the data into training and testing sets based on sessions.
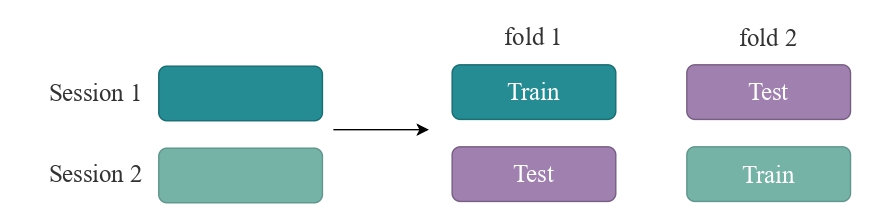
The inner cross-validation strategy can be changed by passing the cv_class and cv_kwargs arguments. By default, it uses LeaveOneGroupOut, which performs Leave-One-Session-Out cross-validation.
- Parameters:
cv_class (cross-validation class, default=LeaveOneGroupOut) – Inner cross-validation strategy for splitting the sessions of one subject. LeaveOneGroupOut is the most common default.
shuffle (bool, default=False) – Whether to shuffle the session order for each subject. It can only be used when changing the cv_class to a class compatible with shuffle.
random_state (int, RandomState instance or None, default=None) – Controls the randomness of the inner cross-validation when shuffle is True. Pass an int for reproducible output across multiple function calls. For cv_class accepting random_state, they are provided with a shared rng.
cv_kwargs (dict) – Additional arguments to pass to the inner cross-validation strategy.
- Yields:
train (ndarray) – The training set indices for that split.
test (ndarray) – The testing set indices for that split.
- get_n_splits(metadata)[source]#
Return the number of splits for the cross-validation.
The number of splits is the number of subjects times the number of splits of the inner cross-validation strategy.
We try to keep the same behaviour as the sklearn cross-validation classes.
- Parameters:
metadata (pd.DataFrame) – The metadata containing the subject and session information.
- Returns:
n_splits – The number of splits for the cross-validation
- Return type:
- split(y, metadata)[source]#
Generate indices to split data into training and test set.
- Parameters:
X (array-like of shape (n_samples, n_features)) – Training data, where n_samples is the number of samples and n_features is the number of features.
y (array-like of shape (n_samples,)) – The target variable for supervised learning problems.
groups (array-like of shape (n_samples,), default=None) – Group labels for the samples used while splitting the dataset into train/test set.
- Yields:
train (ndarray) – The training set indices for that split.
test (ndarray) – The testing set indices for that split.